Python 進階:資料清理到視覺化一步到位

陳子傑
GDG on Campus NTPU 核心幹部 技術組組長
- 『北大 APP』專案負責人
- 擅長操作、教學 Flutter 以及 Firebase
隨著十一月迎來尾聲,《Python:從 0 開始數據分析》系列也進入最後一堂社課啦~ 這次我們將著重在把前兩週的基礎語法與進階操作實際應用於「數據分析」領域中。話不多說,馬上跟著我們的腳步,一起來回顧這次的社課內容吧!
一、關於資料分析可能讓你很好奇的 point
| 資料是什麼,電腦看得懂嗎?
當各種網站想要上傳開放資料,一般都會將資料轉為 .csv 檔案,而 .csv 檔案(Comma-Separated Values,逗號區隔檔案)是一種常見且通用性強的資料儲存格式,各個資料欄位皆會由逗號分隔。
在這次的課程中,我們將利用 Python 的兩個函式庫,協助我們進行資料抓取與整理,以及資料視覺化等操作。
| 資料處理流程
- 資料取得:從政府平臺或其他開放數據平臺下載資料。
- 資料預處理:清理和整理資料,包含刪除不需要的欄位、處理重複資料、轉換資料格式...等。
- 資料分析:利用數據運算和分組技術,計算指標或生成摘要。
- 資料視覺化:使用長條圖、折線圖等圖表呈現分析結果。
- 洞察與應用:根據分析結果提出結論,最終應用於實際決策或研究中。
二、簡易資料分析工具箱
| 從政府公開資訊開始
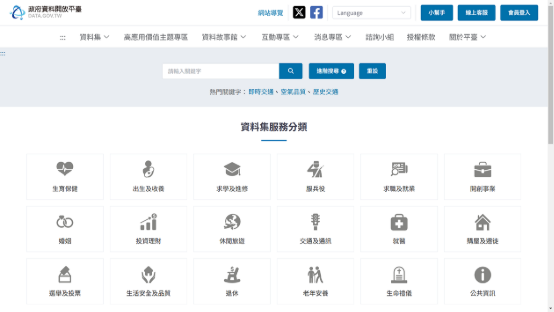 政府資料開放平臺資料集類別
政府資料開放平臺資料集類別
政府資料開放平臺為各機關於職權範圍內取得或做成,且依法得公開之各類電子資料,包含文字、數據、圖片、影像、聲音、詮釋資料(metadata)等,以開放格式於網路公開,提供個人、學校、團體、企業或政府機關等使用者,依其需求連結下載及利用。
| 兩大常用函式庫
 兩種函式庫的功能比較
兩種函式庫的功能比較
三、資料分析範例 — 空氣品質預報
| 資料取得
Step1. 使用 pandas 的 .read_csv() 方法讀取資料(此處示範資料之來源為政府資料開放平臺中的「空氣品質預報資料」)。
- 首先進入連結,到下載
.csv檔案的地方點擊右鍵 -> 複製連結網址。
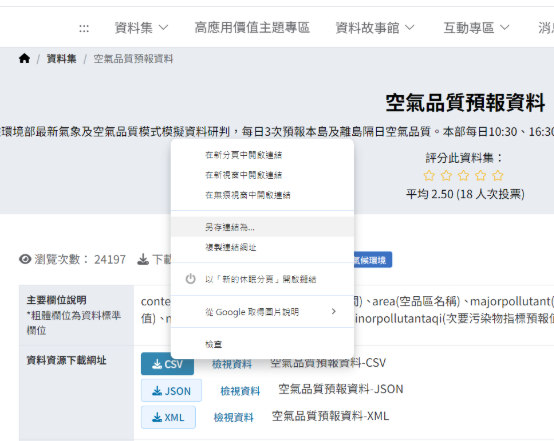 首先複製連結網址
首先複製連結網址
- 接著將網址填入下方程式碼,如此處範例所示:
import pandas as pd
import matplotlib.pyplot as plt
path = '剛剛複製的網址'
df = pd.read_csv(path)
Step2. 利用 df = pd.read_csv(path) 將資料讀取到 DataFrame。
- 使用
pandas的read_csv函數,將.csv檔案中的資料讀取並存儲到名為df的 DataFrame 中。 - 你可以想像將 Excel 表格的資料塞到變數
df當中。
| 資料預整理
1. 查看資料的欄位名稱
首先,我們可以使用 print(df.columns) 來查看資料中每個欄位(column)的名稱:
 執行結果
執行結果
根據執行結果可知,標籤有 content、publishtime…等,從這些欄位名稱,我們可以推測:資料的第一行是「說明」欄位,第二行是「發布時間」欄位,依此類推。
2. 丟掉不要的資訊
因為我們要分析「同一地區的各時間平均」以及「一個時間內各地的平均」,故我們真正要的資訊只有 area、forecastdate、aqi,使用以下程式碼刪除 publishtime、content、majorpollutant、minorpollutant、minorpollutantaqi 等不必要的欄位:
df.drop(['publishtime','content', 'majorpollutant','minorpollutant','minorpollutantaqi'], axis=1, inplace=True)
# axis=1 指定要刪除的是欄位(columns),而不是行(rows)。
# inplace=True 表示直接在原 DataFrame 上修改資料,而不是返回一個新的 DataFrame。
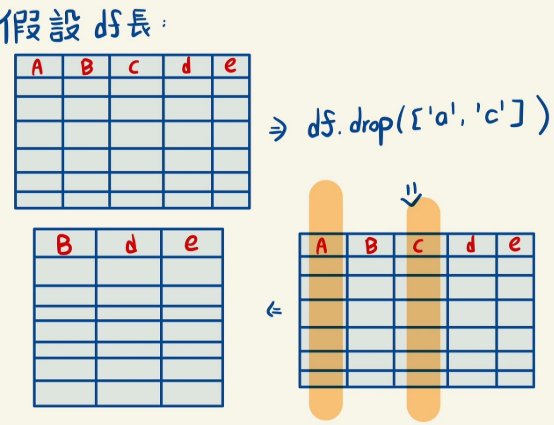 將不要的標籤行都刪除,並且 inplace=True 表示我們直接在原 DataFrame 上進行修改,而不返回新的 DataFrame
將不要的標籤行都刪除,並且 inplace=True 表示我們直接在原 DataFrame 上進行修改,而不返回新的 DataFrame
如果你夠細心,你可能會發現這原資料的毛病——在原始資料中,有一些資料是重複登記的!我們可以輸入 df.drop_duplicates() 刪除重複資訊。
 概念示意圖
概念示意圖
| 資料分析
1. 找到日期最大值與最小值
# 將 'forecastdate' 欄位轉換為日期時間物件
df_unique['forecastdate'] = pd.to_datetime(df_unique['forecastdate'])
# 找到最早和最晚的日期
earliest_date = df_unique['forecastdate'].min()
latest_date = df_unique['forecastdate'].max()
print("最早日期:", earliest_date.strftime('%Y/%m/%d'))
print("最晚日期:", latest_date.strftime('%Y/%m/%d'))
- 找到資料中的「預測時間最大與最小值」,有助於我們等等做圖表。
- 將日期轉成時間物件後,找到在
forecastdata欄位中的最大與最小值,並利用strftime('%Y/%m/%d')顯示,將日期物件格式化為YYYY/MM/DD的字串。
2. 資料更正(Mapping / Replace) — 將資料中的中文轉換成英文
在資料中,有些欄位可能是中文名稱,為了方便後續分析,可以將這些中文轉換成英文。以 area 欄位為例,我們可以使用字典對應(Mapping)概念進行替換:
area_mapping = {
'北部': 'North',
'竹苗': 'Zhubei',
'中部': 'Central',
'雲嘉南':'YunChiayiTainan',
'高屏': 'KaohsiungPingtung',
'宜蘭': 'Yilan',
'花東': 'HualienTaitung',
'馬祖': 'Matsu',
'金門': 'Kinmen',
'澎湖': 'Penghu'
}
df_unique['area'] = df_unique['area'].replace(area_mapping)
3. 根據組別分組並取平均值
接下來,我們希望計算每個地區在指定時間區間內的平均 AQI 值。這樣可以讓我們了解各地區空氣品質的整體表現。為此,我們需要根據 area 欄位對資料進行分組,然後計算每個地區的平均 AQI 值:
area_aqi = df_unique.groupby('area')['aqi'].mean()
print(area_aqi)
groupby('area'):將資料按照area列的值進行分組,將所有具有相同area標籤的資料集合在一起。['aqi'].mean():對每個相同地區的分組計算aqi欄位的平均值。
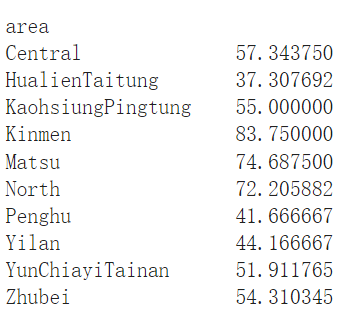 print(area_aqi) 執行結果
print(area_aqi) 執行結果
| 資料視覺化
根據前面計算出來的 area_aqi 變數,我們可以製作長條圖來表示每個地區的 AQI 值。以下是程式碼範例:
area_aqi.plot(kind='barh') # 使用水平長條圖來表示每個地區的 AQI 值
plt.xlabel('Avg AQI') # 設定 X 軸的標籤名稱
plt.ylabel('Area') # 設定 Y 軸的標籤名稱
plt.title('Each Area AQI from ' + earliest_date.strftime('%Y/%m/%d') + ' to ' + latest_date.strftime('%Y/%m/%d')) # 設定圖表標題
plt.savefig('area_aqi_chart.png') # 儲存圖表為 PNG 檔案
plt.show() # 顯示圖表
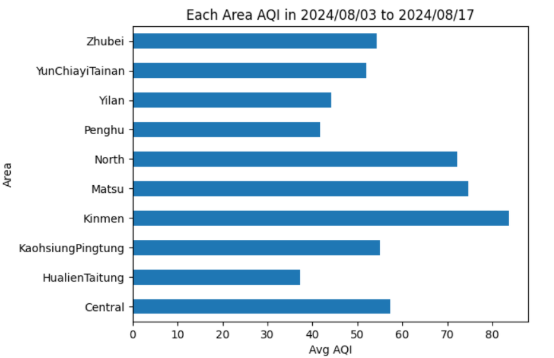 上述程式執行結果
上述程式執行結果
| 應用練習(附參考解答)
根據時間分類,評判各時段下所有地區的平均 AQI 數值,並以折線圖表示。
💡 提示:
- 該怎麼讓同日期的人在同一組...?
- 若使用
plot(kind='line')方法來畫出折線圖,如何宣告 XY 軸名稱?
# 參考解答
# 根據日期進行分組並計算平均 AQI 值
date_aqi = df_unique.groupby('forecastdate')['aqi'].mean()
# 使用折線圖表示各日期的平均 AQI 值
date_aqi.plot(kind='line')
# 設定 XY 軸的標籤名稱
plt.xlabel('Date')
plt.ylabel('Avg AQI')
# 設定圖表標題
plt.title('Average AQI per Day from ' + earliest_date.strftime('%Y/%m/%d') + ' to ' + latest_date.strftime('%Y/%m/%d'))
# 顯示圖表
plt.show()
六、進階補充 — Kaggle 簡介與入門
Kaggle 是一個為資料科學和機器學習愛好者設計的平臺,也是全世界公認最大的資料科學社群,目前提供以下功能與資源:
- 擁有大量公開的資料集,涵蓋各種主題:電影評論、電子商務、醫療數據等。
- 可直接在 Kaggle Notebook 中下載與處理資料,無需本地環境設置。
- 提供各式機器學習競賽,從初學者到進階者都有適合的挑戰。常見主題包括分類、迴歸、圖像處理和自然語言處理。
今天我們的教材皆上傳在 Google Colab(一個可以寫程式的雲端平臺)中,而如果你想要在裡面使用 Kaggle 資料集,可以直接將資料集下載到 Colab 的虛擬機器中,避免使用本地端資源——而這需要獲取 Kaggle API* 認證後才能進行。
*補充:何謂 API?
API(Application Programming Interface,應用程式介面)
是一組定義了不同軟體或系統之間如何互動的規範。
它允許開發人員在不需要了解其他軟體內部運作原理的情況下,
就可以透過簡單的指令訪問其他軟體的功能。
簡單來說,使用 Kaggle API 就像是在 Colab 中安裝一個「通道」,
通過這個通道,Colab 可以向 Kaggle 請求資料集或競賽相關資料,
再由 Kaggle 將資料集或資訊傳回給 Colab,
讓你可以直接在 Colab 中使用這些資料進行分析和建模。
所以你不用把資料集下載到本地端,就能直接利用 Colab 的虛擬機器來處理數據。
於 Kaggle 官網註冊帳號後,具體的操作步驟如下:
 首先進入[此網站](https://kaggle.com/datasets/brendan45774/test-file),並點擊「Settings」
首先進入[此網站](https://kaggle.com/datasets/brendan45774/test-file),並點擊「Settings」
 接著點擊 Account -> API 中的「Create New Token」,就能夠以 .json 檔案格式下載你的 API 金鑰了
接著點擊 Account -> API 中的「Create New Token」,就能夠以 .json 檔案格式下載你的 API 金鑰了
拿到 Token 後,你可以在本地執行以下程式:
!pip install kaggle # 安裝 Kaggle API 客戶端
from google.colab import files # 上傳 Kaggle API 金鑰(需要手動操作)
files.upload() # 此處系統會提示你上傳 kaggle.json 檔案
# 設置 Kaggle API 認證
import os
os.environ['KAGGLE\_CONFIG\_DIR'] = "/content" # 設定 Kaggle 認證目錄
執行過程中,系統會要求你上傳將剛剛下載到的 .json(即 Kaggle API)檔案,完成上傳後,你的 Google Colab 空間就能夠使用 Kaggle 資料集了!
*在 Colab 中使用 Kaggle API 時,可以輸入 !kaggle datasets download -d <dataset-name>(<dataset-name> 是 Kaggle 資料集頁面上的路徑名)。
之後就跟前面所述一樣,可以開始進行資料分析囉!
# 使用範例
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 讀取 Kaggle 中的 Titanic 資料集
df = pd.read_csv('/content/Titanic-Dataset.csv')
七、自動化腳本執行 Python 檔案
⚠️ 注意:以下教學僅適用於 Windows 作業系統。
| 前言
如果你也遇到過這些情況:
- 希望能夠定時自動運行 Python 程式。
- 網路爬蟲需要每天獲取最新數據,因此每次都需要手動運行程式。
- 曾經為了實現自動化而花費了金錢購買第三方工具。
那麼你來對地方了!這次教大家撰寫的自動化腳本,就可以輕鬆幫你解決以上問題。
本次教學中,我們會用到以下工具跟概念,在這邊先做簡單的說明:
- BAT 檔案(批處理檔案)是一種腳本文件,在 Microsoft Windows 操作系統中可用來自動執行一系列命令。
- 工作排程器(Task Scheduler)是 Windows 系統中的工具,用來在預定時間或特定條件下自動執行程序或腳本。
- Windows 工作排程器是一個內建的工具,允許用戶設定、管理和自動執行排程任務,並提供了多種觸發條件和執行選項。
| 實際操作
1. 事前準備
- 下載教材:點擊這個連結進到 Colab,並下載
.py檔案,把它放在你方便的任何位置(請選擇一個容易記得的路徑,以便後續的進一步操作)。
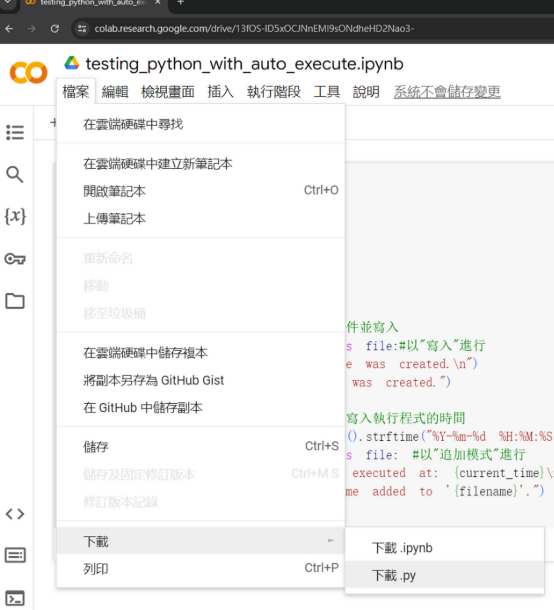 於 Colab 中下載 .py 檔案
於 Colab 中下載 .py 檔案
- 在本文的演示範例裡,我們在桌面創建一個資料夾,並將檔案放在裡面(注意:由於某些程式或腳本可能無法正確處理中文路徑,為避免讀取錯誤,建議使用英文或數字幫該資料夾取名):
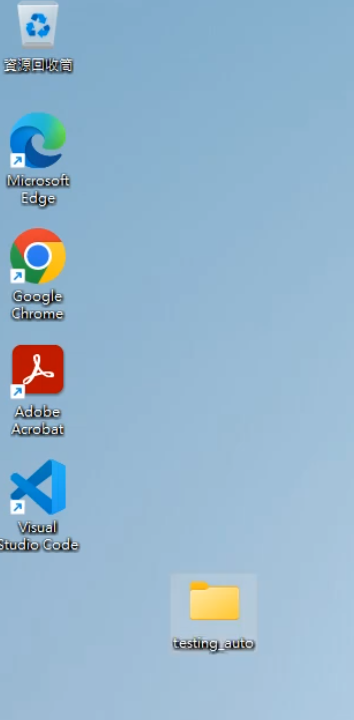
- 到 Python 官網下載安裝包,讓電腦能跑動
.py檔案。
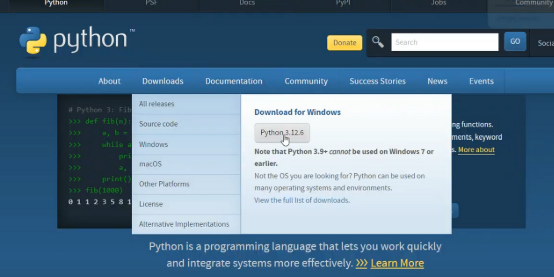 選擇最新版本即可(注意:應下載符合自己電腦位元系統的安裝包)
選擇最新版本即可(注意:應下載符合自己電腦位元系統的安裝包)
2. 開始編寫自動化腳本
- 在你想要存放腳本檔案的任何位置,建立一個
.txt純文字檔案,並寫入兩行程式:
cd 剛剛建立的檔案夾位置 # 可以在 Windows 檔案總管中查詢路徑
python 檔案名稱.py
例如:若我們把檔案放在這個路徑下方:
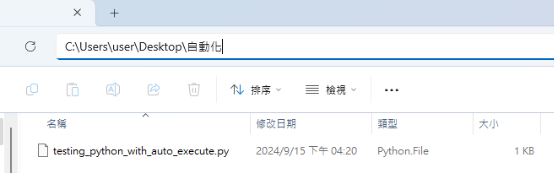
則 .txt 檔案中將寫到:
cd C:\Users\user\Desktop\自動化 # 注意要使用反斜線(\)哦!
python testing_python_with_auto_execute.py # 若剛剛有順利安裝 Python 才能執行
- 直接更改副檔名,將
.txt檔案轉成.bat檔案(腳本檔案)。
- 檢查:當你完成以上任務後,可以點開
.bat檔看看,如果點擊完後,Python 有創立一個.txt檔案的話,那就是成功了!
5. 讓電腦自動跑動 .bat 檔案
- 在電腦中搜尋「工作排程器」並開啟。
- 在「工作排程器 (本機)」上按右鍵,點擊「建立工作」:
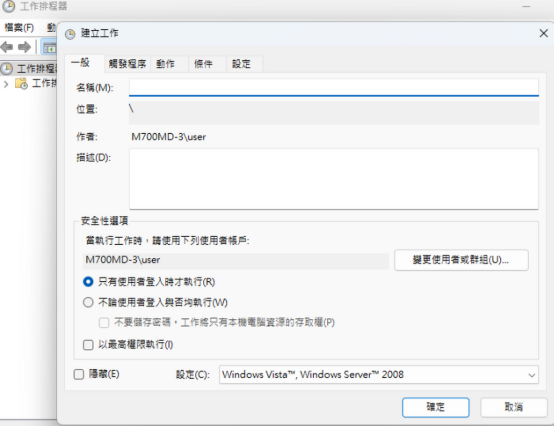 最上方的「工作名稱」可以隨意取一個,但為了方便辨識,建議選擇一個具描述性的名字。
最上方的「工作名稱」可以隨意取一個,但為了方便辨識,建議選擇一個具描述性的名字。
- 點擊上方列表中的「觸發程序」,並編寫觸發條件:
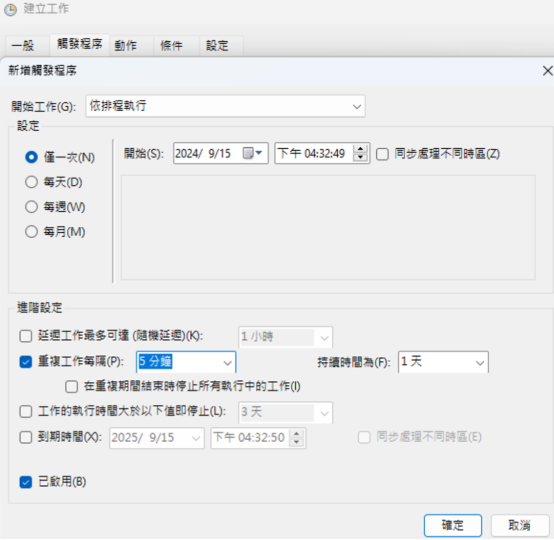 我們以「每五分鐘就驅動一次」為例
我們以「每五分鐘就驅動一次」為例
- 點擊上方列表中的「動作」->「瀏覽」,找到剛剛建立的
.bat檔案後,選擇它,將其新增進去,並點選下方的「確定」:
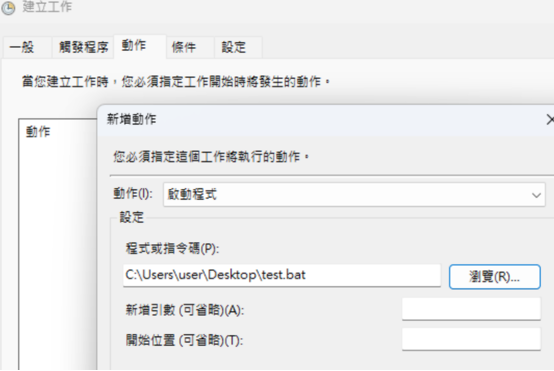
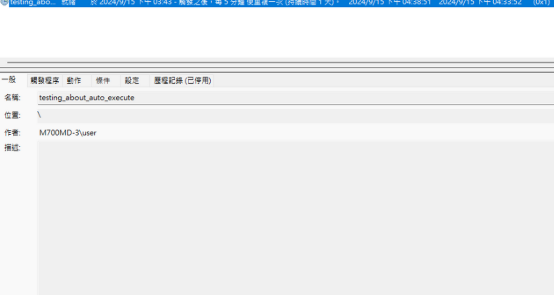
- 接下來,你可以點進工作排程器的左欄的「工作排程器程式庫」,就能看到我們新增的指令了!
| 教學影片
如果文字看得不夠清楚,可以跟著下方的影片一起操作一遍,約 5 分鐘就能設置完成~
感謝看到這裡的大家,《Python:從 0 開始數據分析》系列課程就到這邊結束啦,希望這系列有幫助到大家!