Python 自動化爬蟲

施尚丞
GDG on Campus NTPU 副社長
- 現任蕭宇翔教授研究助理,執行產學計畫&科技部大專生研究計畫
- 曾任和泰汽車 Toyota、台灣大哥大 Disney+ 實習生

在認識爬蟲基礎知識與相關套件後,現在輪到你動手試試看啦~ 在這次的實作中,我們會利用校內的課程查詢系統找出「自己所屬學院在 112 學年的所有課程資訊」(包含中文名稱、英文名稱、系級、學分、時數等)。
歡迎自由下載或查看當天的 GitHub 程式碼,一起 step by step 地跟著操作(須預先安裝 Python 開發環境,並下載 DrissionPage 套件)!
| Step 0. 思考爬蟲流程
如前文所述,爬蟲正是藉由打造一個重複模擬人類動作的機器人,來一一抓取我們需要的資料,因此想想看你平常是怎麼查詢資料的,就會知道我們要怎麼做啦!以此次目標為例,一般我們的操作流程會像這樣:
- 點擊網頁(北大課程查詢系統)
- 選擇想要的搜尋方式
- 選擇學院、學年、學期等條件
- 點擊搜尋
- 等待網頁載入
- 查看資料
- 把有用的資料爬取下來
| Step 1. 匯入套件,進入課程查詢系統
# 須注意 Python 版本是否兼容(講者使用 3.11.2)
from DrissionPage import errors from DrissionPage import ChromiumPage
# 設定要去的目標網頁 url = "https://sea.cc.ntpu.edu.tw/pls/dev\_stud/course\_query\_all.chi\_main"
# 初始化瀏覽器設定 page = ChromiumPage()
# 讓瀏覽器開啟網頁 page.get(url)
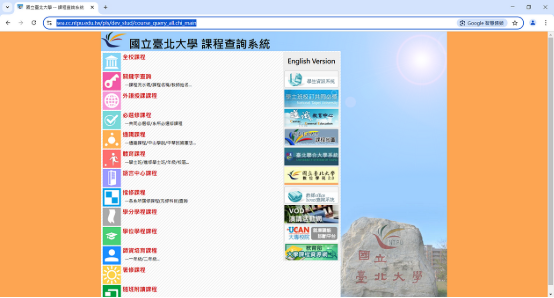 這一步成功時,程式會自動開啟一個瀏覽器視窗,並前往[北大課程查詢系統的首頁](https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.chi_main)
這一步成功時,程式會自動開啟一個瀏覽器視窗,並前往[北大課程查詢系統的首頁](https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.chi_main)
| Step 2. 選擇搜尋方式
在成功進入網頁後,可點擊滑鼠右鍵清單中的「檢查」,並:
- 收合不必要的區塊,讓標籤結構更清晰。
- 觀察對應的 HTML 標籤,找出關鍵元素。
- 使用 DrissionPage 定位元素(標籤名稱前加 .)。
- 若標籤有多個,使用中括號 [] 來選取對應的索引值。
# 初始化並打開頁面 url = "https://sea.cc.ntpu.edu.tw/pls/dev\_stud/course\_query\_all.chi\_main"
# 初始化瀏覽器設定 page = ChromiumPage() page.get(url)
# 找到頁面的所有 tr rows = page.eles(".titletext") # print(len(rows)) # 印出有幾個 tr
# 找到第一個 row = rows[0] row.click()
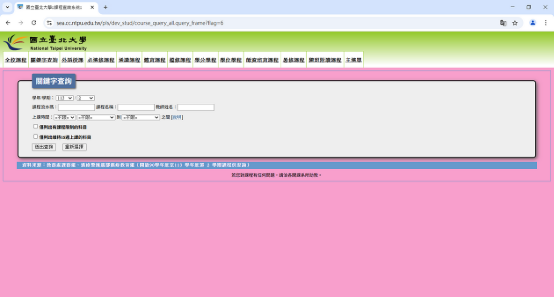 若上述步驟順利,程式會回傳 true,並讓電腦自動進入[這個畫面](https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.query_frame?flag=6)
若上述步驟順利,程式會回傳 true,並讓電腦自動進入[這個畫面](https://sea.cc.ntpu.edu.tw/pls/dev_stud/course_query_all.query_frame?flag=6)
| Step 3. 自動選擇篩選條件
方法一:直接輸入
- 點擊「學士班」,檢查 HTML 結構*。*
- 使用 page.wait(1) 避免程式執行速度過快導致錯誤*。*
- 選取學院名稱,輸入對應學院*。*
- 輸入學年、學期*。*
方法二:使用 XPath
XPath 可以理解為門牌地址(具唯一性),我們可以透過它找到需要的條件。
- 直接點擊學年/學期,選擇「檢查」。
- 右鍵選擇「 Copy」 →「Copy XPath」。
- 貼上 XPath 於 semester_option = page.ele() 內*。*
補充:因為網頁需要載入的時間,因此在後端渲染的爬蟲中,經常需要等待(page.wait(秒數)),故我們會在每個頁面跳轉動作之間新增等待秒數,確保網頁載入完成後再進行下一步動作(這樣做的同時,也可以避免請求次數過多,導致訪問被封鎖)。
# 初始化並打開頁面 url = "https://sea.cc.ntpu.edu.tw/pls/dev\_stud/course\_query\_all.chi\_main"
# 初始化瀏覽器設定 page = ChromiumPage() page.get(url)
# 找到頁面的所有 tr rows = page.eles(".titletext")
# 找到第一個 row = rows[0] row.click()
# 有一個 select 的選單 select = page.eles("xpath://input[@type='radio']") page.wait(1) becholar = select[1] # 學士班是第二個 becholar.click()
# 找到學院的選單 dep = page.eles("xpath://select")[0] dep.click()
# 選擇你要的學院 dep_option = page.ele("xpath://option[contains(text(),'人文學院')]") dep_option.click() page.wait(1)
# 找到開課的選單 year = page.eles("xpath://select")[2] year.click()
# 選擇你要的開課年度 year_option = page.ele("xpath://option[contains(text(),'112')]") page.wait(1) year_option.click()
# 找到學期的選單 semester = page.eles("xpath://select")[3] semester.click()
# 選擇你要的學期 semester_option = page.ele("xpath:/html/body/center/table/tbody/tr/td/table/tbody/tr[1]/td/fieldset/form[2]/p[3]/select[2]/option[1]") page.wait(1) semester_option.click()
# 按下輸入鍵,跳轉到課程查詢的頁面(如下圖)
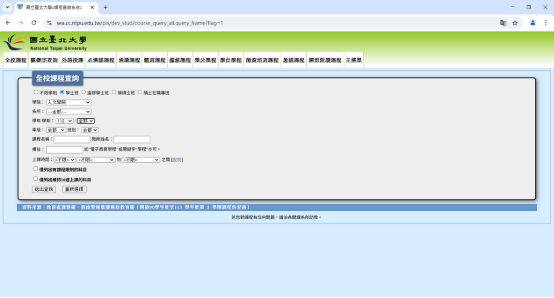 若上述步驟成功,則網頁會自動設定如圖(以「查詢文院學士班於 112 學年度開設課程清單」為例)
若上述步驟成功,則網頁會自動設定如圖(以「查詢文院學士班於 112 學年度開設課程清單」為例)
| Step 4. 點擊搜尋
- 使用 XPath 定位搜尋按鈕。
- 設定 type="submit"。
- 確認頁面成功跳轉至課程列表。
# 初始化並打開頁面 url = "https://sea.cc.ntpu.edu.tw/pls/dev\_stud/course\_query\_all.chi\_main"
# 初始化瀏覽器設定 page = ChromiumPage() page.get(url)
# 找到頁面的所有 tr rows = page.eles(".titletext")
# 找到第一個 row = rows[0] row.click() page.wait(1)
# 有一個 select 的選單 select = page.eles("xpath://input[@type='radio']") page.wait(1) becholar = select[1] becholar.click() # page.wait(1)
# 找到學院的選單 dep = page.eles("xpath://select")[0] dep.click()
# 選擇你要的學院 dep_option = page.ele("xpath://option[contains(text(),'人文學院')]") dep_option.click() page.wait(1)
# 找到開課的選單 year = page.eles("xpath://select")[2] year.click() year_option = page.ele("xpath://option[contains(text(),'112')]") page.wait(1) year_option.click() page.wait(1)
# 找到學期的選單 semester = page.eles("xpath://select")[3] semester.click() # semester_option = page.ele("xpath://option[contains(text(),'全部')]") semester_option = page.ele("xpath:/html/body/center/table/tbody/tr/td/table/tbody/tr[1]/td/fieldset/form[2]/p[3]/select[2]/option[1]") page.wait(1) semester_option.click()
# 找到查詢按鈕包含文字"送出查詢" # 使用 CSS 選擇器找到 type 屬性為 submit 的按鈕 submit = page.ele('@type=submit') # 記得加上@ submit.click()
# 成功回傳 print("成功")
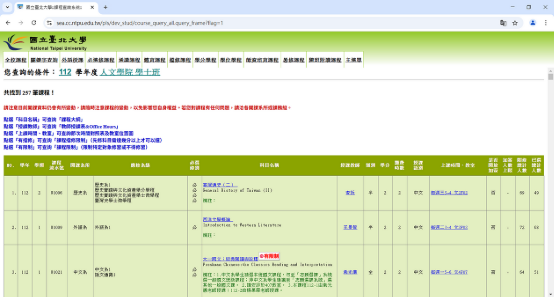 若上述步驟成功,則程式會回傳「成功」,並促使網頁跳轉到課程查詢的頁面
若上述步驟成功,則程式會回傳「成功」,並促使網頁跳轉到課程查詢的頁面
| Step 5. 爬取課程連結
- 課程資料存在於不同的網頁,因此需要逐一提取連結。
- 觀察
標籤內的
來獲取所有課程連結。 - 若遇到網址缺失,檢查缺少部分並補全。
# 初始化並打開頁面 url = "https://sea.cc.ntpu.edu.tw/pls/dev\_stud/course\_query\_all.chi\_main"
# 初始化瀏覽器設定 page = ChromiumPage() page.get(url)
# 找到頁面的所有 tr rows = page.eles(".titletext")
# 找到第一個 row = rows[0] row.click() page.wait(1)
# 有一個 select 的選單 select = page.eles("xpath://input[@type='radio']") page.wait(1) becholar = select[1] becholar.click() # page.wait(1)
# 找到學院的選單 dep = page.eles("xpath://select")[0] dep.click()
# 選擇你要的學院 dep_option = page.ele("xpath://option[contains(text(),'人文學院')]") dep_option.click() page.wait(3)
# 找到開課的選單 year = page.eles("xpath://select")[2] year.click() year_option = page.ele("xpath://option[contains(text(),'112')]") page.wait(1) year_option.click() page.wait(1)
# 找到學期的選單 semester = page.eles("xpath://select")[3] semester.click() # semester_option = page.ele("xpath://option[contains(text(),'全部')]") semester_option = page.ele("xpath:/html/body/center/table/tbody/tr/td/table/tbody/tr[1]/td/fieldset/form[2]/p[3]/select[2]/option[1]") page.wait(1) semester_option.click()
# 找到查詢按鈕包含文字"送出查詢" submit = page.ele('@type=submit') submit.click() # 成功回傳 print("成功")
# 定位到目標 table 元素 table_element = page.ele('xpath:/html/body/div[2]/table')
# 獲取 table 元素下的所有
元素 tr_elements = table_element.eles('tag:tr') #這個是 DrissionPage 的寫法 links_info = [] for tr_element in tr_elements: 元素中查找 元素 # 遍歷並輸出超連結信息 for link_info in links_info:
| Step 6. 確認第一筆資料是否正確
- 儲存為 Excel 檔案。
- 最後一行也可以改成:print("成功儲存到 C:\Users\(使用者名稱)\Desktop\112_ort_course_links.xlsx")。
import pandas as pd
# 轉換為 DataFrame df = pd.DataFrame(links_info)
# 儲存成 Excel 檔案 excel_path = "C:\Users\SHI\Desktop\112_art_course_links.xlsx" df.to_excel(excel_path, index=False) print(f"成功儲存到 {excel_path}")
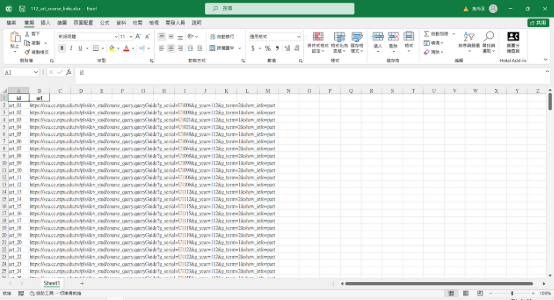 執行完畢後會生成的 Excel 檔案
執行完畢後會生成的 Excel 檔案
| Step 7. 爬取所有目標資料
- 讀取 Excel 檔案。
- 若發生讀取錯誤,可嘗試:
- 將所有 \ 替換為 \。
- 在路徑前加上 r"" 以避免跳脫字元錯誤。
# 未安裝 BeautifulSoup、requests、pandas、openpyxl 套件者, # 可在終端輸入下列指令下載: # !pip install BeautifulSoup4 # !pip install requests # !pip install openpyxl
# *欲查看目前安裝了哪些套件,可輸入: # !pip list #(由於開發環境可能不同,上述程式碼若執行錯誤,可嘗試去除開頭驚嘆號再試一次)
import pandas as pd import re from DrissionPage import WebPage
# 讀取 Excel 檔案 excel_path = r"C:\Users\SHI\Desktop\112_art_course_links.xlsx" df = pd.read_excel(excel_path) # 讀取 Excel urls = df.iloc[:, 1].dropna().tolist() # 假設 URL 在第 2 欄,去除空值 print(urls[0:3]) # 測試前 3 個網址
# 初始化瀏覽器 page = WebPage() # 存儲爬取結果 course_data = []
# 定義要解析的欄位(正則匹配) pattern = {
# 存入 DataFrame df_output = pd.DataFrame(course_data) # 儲存成 Excel 檔案 output_path = r"C:\Users\SHI\Desktop\112_art_course_info.xlsx" df_output.to_excel(output_path, index=False) print(f"成功儲存到 {output_path}") # 大功告成!
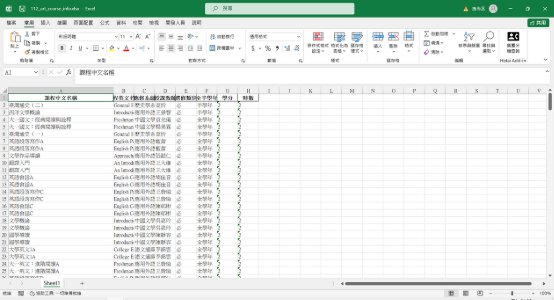 最終產出
最終產出
恭喜看到這裡的每一位夥伴,你成功學會一項相當實用的技術!看著電腦自動幫自己做事,想必很有成就感吧~ 也相信讀到這裡的你已經掌握了 DrissionPage 的基本用法,並能夠模擬人工操作來爬取網頁資料。
若有興趣更上層樓,同學也可以進一步學習動態網站爬取、反爬機制應對、數據清理與儲存等,以提升爬蟲的靈活度與實用性哦~