Python 自動化爬蟲

施尚丞
GDG on Campus NTPU 副社長
- 現任蕭宇翔教授研究助理,執行產學計畫&科技部大專生研究計畫
- 曾任和泰汽車 Toyota、台灣大哥大 Disney+ 實習生

講座內容摘要
這學期的目標是製作個人化的聊天機器人,當中可能會運用到各式各樣的資料,而我們需要的資料將會成為聊天機器人的回答依據。
除此之外,我們也可能會透過資料微調(Fine-tuning)AI 模型,或是建立 RAG(Retrieval-Augmented Generation,AI 的圖書館)來優化聊天機器人的應答表現。因此,在開發聊天機器人或 AI 應用時,如何獲取可用數據便是非常關鍵的一環。
一、從網路撈資料不是夢 — 認識爬蟲前的基礎知識
| 資料也有分種類?一次搞懂其類型
在爬取網頁時,會遇到各種不同的資料格式。了解這些資料類型,有助於選擇合適的解析方式與存儲方法。
- 結構化資料(Structured Data)
- 定義:資料通常為由直欄和橫列構成的表格,可以直接解析和儲存。
- 常見來源:資料庫(SQL, NoSQL)、JSON / XML API 回應、CSV / Excel 表格(如下圖)。
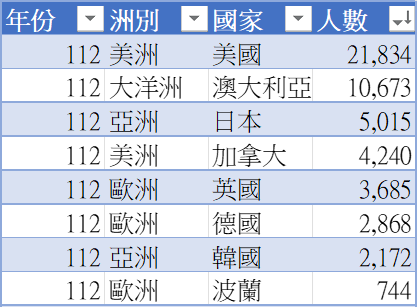 112 年度部分國家之我國留學生人數統計表
112 年度部分國家之我國留學生人數統計表
2. 非結構化資料(Unstructured Data)
- 定義:沒有固定結構,或者尚未以預先定義方式排序的資料,需要進一步處理才能使用。
- 常見來源:文章 / 新聞 / 論壇貼文、社群媒體貼文(Instagram、Twitter)、圖片 / 影片 / 音訊
3. 半結構化資料(Semi-Structured Data)
- 定義:資料雖然有結構,但不是完全固定的格式。
- 常見來源:HTML 網頁內容、Email 電子郵件、Markdown、YAML
 Email 資料釋例
Email 資料釋例
| 網頁是怎麼「長出來」的?搞懂前後端渲染差異!
簡單來說,「渲染」就是將你寫的程式碼轉成 HTML!以下就讓我們透過爬蟲視角,向大家解釋何謂「前端渲染」 與「後端渲染」。 1. 後端渲染網頁(Server-Side Rendering, SSR)
- 定義:由伺服器生成完整的 HTML,瀏覽器直接接收可顯示的內容。
- 特徵:檢視原始碼時能看到完整內容、首次載入時頁面已包含所有資料、網頁原始碼內容與瀏覽器顯示內容基本一致。
- 爬取方式:最適合用 requests + BeautifulSoup,因為所有內容都在 HTML 中。
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
data = soup.find_all("div", class\_="content")
2. 前端渲染網頁(Client-Side Rendering, CSR)
- 定義:伺服器只提供基本 HTML 結構和 JavaScript,實際內容由瀏覽器執行 JS 後動態生成。
- 特徵:檢視原始碼時看不到完整內容(只有空的容器和 JS 代碼)、需要等待 JavaScript 執行後才能看到完整內容、通常通過 API 獲取數據並在前端渲染、常見於現代 SPA(Single Page Application)應用,如透過 React、Vue 或 Angular 開發的網站
- 爬取方式:
(1) 使用 Selenium 或 DrissionPage 等瀏覽器自動化工具。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
# 等待 JavaScript 執行完成
driver.implicitly_wait(5)
# 現在可以提取完整內容
elements = driver.find_elements(By.CLASS_NAME, "content")
driver.quit()
(2) 透過分析並直接調用網站的 API(更高效)。
import requests
api_url = "https://api.example.com/data"
headers = {
` `"User-Agent": "Mozilla/5.0...",
` `"Referer": "https://example.com"
}
response = requests.get(api_url, headers=headers)
data = response.json()
補充:判斷網站是前端渲染還是後端渲染的方法
- 檢視原始碼對比顯示內容:如果原始碼中看不到你在瀏覽器中看到的內容,很可能是前端渲染。
- 檢查網絡請求:使用瀏覽器開發者工具中的「Network」標籤,前端渲染網站通常會有對 API 的 XHR 或 Fetch 請求。
- 網站技術堆棧:使用 React、Vue、Angular 等前端框架的網站多為前端渲染;使用 PHP、Django、Ruby on Rails 等傳統框架的網站多為後端渲染。
二、資料怎麼來?三種主流數據獲取方式大公開
| 使用現成的公開資料集
適合:基礎模型訓練、快速測試。
- Kaggle:提供大量機器學習和 NLP 相關的數據集,例如對話數據、新聞數據等。
- Google Dataset Search:一個數據集搜尋引擎,可查找來自政府、學術機構和開放社群的數據。
- Hugging Face Datasets:專為 AI 和 NLP 訓練設計的數據集,如 Wikipedia 文本、對話語料庫等。
- **政府 & 企業開放資料(Open Data):**例如臺灣政府開放數據,或美國政府開放數據。
| API 資料獲取
適合:獲取結構化數據、即時更新資訊(API 通常比網路爬蟲更穩定,且不易受網站結構變動影響)。
許多網站都有提供 REST API 或 GraphQL API 供開發者存取數據:
- 社群媒體 API:Twitter API、YouTube Data API、Instagram Graph API...。
- 新聞 & 文章 API:NewsAPI、Google Custom Search API...。
- 電商 & 商品 API:Shopee API、Amazon Product Advertising API...。
- 對話數據 API:OpenAI GPT API、Facebook Messenger API...。
| 網路爬蟲(Web Scraping)
適合:收集最新數據、補充特定領域的知識(爬蟲過程中須注意若請求次數過於頻繁,可能會被平臺封鎖,並得遵守網站的 robots.txt 規範,不能惡意影響伺服器運作)。
- 使用 requests + BeautifulSoup 爬取靜態網頁:
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
data = soup.find_all("p") # 抓取所有 <p> 內的文字
print([p.text for p in data])
- 使用 Selenium 爬取動態網頁(JavaScript 生成內容):
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://example.com")
print(driver.page_source) # 取得完整的動態頁面
driver.quit()
- 常見爬取對象:新聞網站(例:Google News, Yahoo News)、電商數據(例:PChome、蝦皮商品資訊)、社群媒體數據(例:Twitter API、Instagram 資料)。
| 三者的比較與選擇
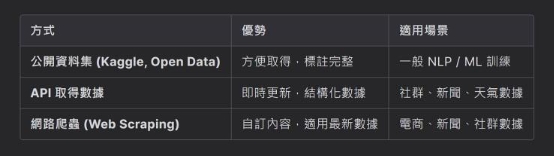 公開資料集 v.s. API v.s. 網路爬蟲比較表
公開資料集 v.s. API v.s. 網路爬蟲比較表
三、什麼是爬蟲?給新手的快速入門指南
| 爬蟲在做什麼?秒懂背後運作原理
「網路爬蟲」(Web Scraping)是一種透過程式模擬瀏覽器訪問網站,進而自動化地擷取網頁資料,並將其轉換成結構化格式,以便進一步處理和分析的技術。爬蟲可以應用於以下領域:
- 資料收集(新聞、商品價格、社群媒體數據)。
- 競品分析(電商比價、趨勢預測)。
- AI 訓練數據準備(蒐集語料訓練聊天機器人)。
- 自動化任務(自動下載、資料同步)。
| 網站其實長這樣?從瀏覽器視角看結構
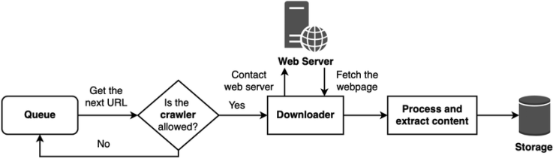 爬蟲流程說明(基本上就是觀察 -> 找共通點/規律 -> 鎖定資料的「門牌號碼」-> 開始爬蟲)
爬蟲流程說明(基本上就是觀察 -> 找共通點/規律 -> 鎖定資料的「門牌號碼」-> 開始爬蟲)
0. 目標網站分析(Target Website Analysis)
- 確定需要爬取的網站與資料類型,例如貼文內容、圖片、用戶互動等。
- 使用瀏覽器開發者工具(F12)或是右鍵檢查,檢視網頁 HTML 結構,確認目標元素所在的標籤與屬性。
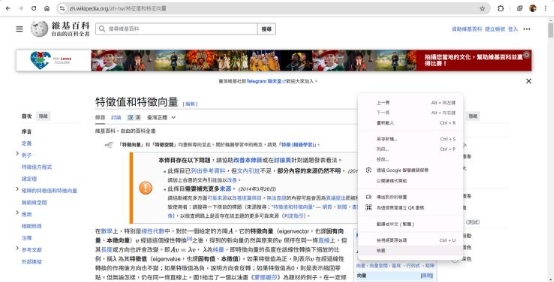 打開滑鼠右鍵選單,點選「檢查」(或直接點按鍵盤上的 F12)
打開滑鼠右鍵選單,點選「檢查」(或直接點按鍵盤上的 F12)
- 檢查 URL 規律,特別是在有分頁、篩選或參數時,確定如何生成請求網址。
1. Queue(URL 隊列)
- 將所有需要爬取的網址放入 URL 隊列(Queue),通常使用清單或佇列結構。
- 程式從 Queue 中取出下一個 URL,進行爬取。
2. 檢查網頁請求允許性(Check Request Permission)
- 在訪問網站前,檢查網站的 robots.txt 文件,確認允許哪些頁面被爬取。
- 使用 HTTP 請求檢查伺服器的回應碼,例如 200 OK 表示允許請求,403 Forbidden 或 401 Unauthorized 表示無法存取。
- 若網站拒絕爬取,則將 URL 放回隊列或略過,並記錄錯誤資訊。
3. Downloader(下載器)
- 程式會使用 Downloader 向網站伺服器發送 HTTP 請求。
- 若網站使用 JavaScript 渲染,需使用 DrissionPage 的瀏覽器模式以模擬使用者行為。
4. Process and Extract Content(解析與擷取內容)
- 獲取 HTML 後,使用 CSS 選擇器或 XPath 方法解析網頁。
- 提取目標元素,例如標題、圖片、文字、按讚數等。
5. Storage(資料儲存)
- 將擷取到的資料儲存於 CSV、JSON 或資料庫中,方便後續分析。
6. 迭代(Loop)
- 若 Queue 中仍有 URL,則重複上述步驟。
| 用爬蟲做點事!IG 貼文資料收集實例
我們今天以「收集 Instagram 公開帳號的貼文內容、按讚數與留言數」為例,向大家演示具體的操作步驟:
步驟 1:目標網站分析 確認 Instagram 的 HTML 結構,檢查貼文內容在
- 中。
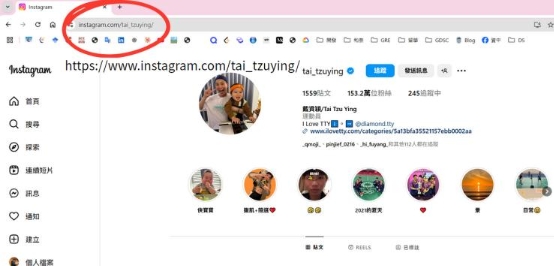
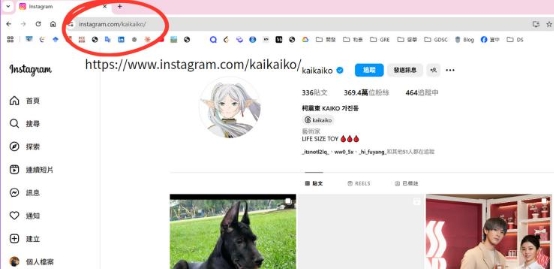
步驟 2:Queue(URL 隊列) 將多個 Instagram 貼文 URL 放入列表 post_urls。
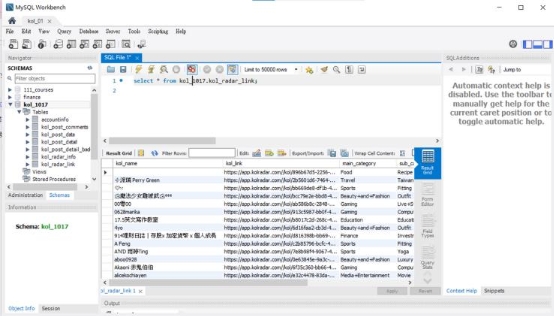
步驟 3:檢查網頁請求允許性 使用 robots.txt 確認允許爬取,並模擬瀏覽器行為。
步驟 4:Downloader(下載器) 使用 DrissionPage 模擬瀏覽器模式,登入帳號以訪問完整內容。
步驟 5:解析與擷取內容
使用 CSS 選擇器抓取 <div>、<span> 和 <ul> 的內容。
步驟 6:儲存資料 將抓取的資料整理為字典,並使用 csv.DictWriter() 將資料寫入 CSV 檔案。
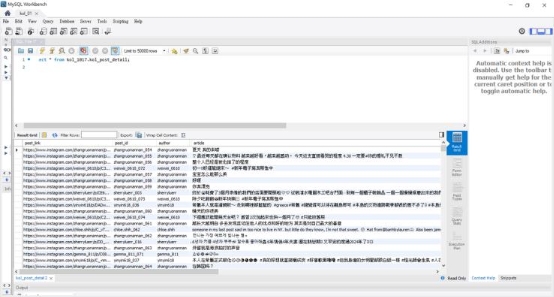
步驟 7:迭代 (Loop) 每次擷取後使用 time.sleep(5) 延遲請求,避免被封鎖。
以下補充程式碼範例:
from DrissionPage.errors import \*
def scrape_instagram_posts(account, target_post_num, connection):
` `""" 爬取 Instagram 貼文資訊並存入資料庫 """
` `page = ChromiumPage()
` `page.get(f'https://www.instagram.com/{account}/')
` `page.wait(5)
` `post_set = set()
` `unique_posts = []
` `post_number = 1
` `post_dict = {}
` `no_new_post_count = 0 # 記錄連續無新貼文次數
` `consecutive_fail_count = 0 # 連續失敗次數
` `total_fail_count = 0 # 累積失敗次數
` `skip_kol=[]
` `#抓取貼文連結
` `for i in range(20):
` `page.scroll.down(80) # 向下滾動
` `page.wait(2) # 等待頁面加載
` `posts = page.eles('.x1lliihq x1n2onr6 xh8yej3 x4gyw5p x1ntc13c x9i3mqj x11i5rnm x2pgyrj') # 重新讀取貼文列表
` `added_new_post = False # 判斷這次爬取是否有新增貼文
` `for post in posts:
` `a_tag = post.ele('.x1i10hfl xjbqb8w x1ejq31n xd10rxx x1sy0etr x17r0tee x972fbf xcfux6l x1qhh985 xm0m39n x9f619 x1ypdohk xt0psk2 xe8uvvx xdj266r x11i5rnm xat24cr x1mh8g0r xexx8yu x4uap5 x18d9i69 xkhd6sd x16tdsg8 x1hl2dhg xggy1nq x1a2a7pz \_a6hd') # 從 post 抓取 <a> 標籤
` `if a_tag:
` `link = a_tag.attr('href')
` `# 篩選符合 "/reel/" 或 "/p/" 的連結
` `if f"{account}/reel/" in link or f"{account}/p/" in link:
` `if link not in post_set:
` `# 數據
` `try:
` `try:
` `post.scroll.to_half()
` `post.hover()
` `except NoRectError:
` `print("無法定位該元素,跳過該貼文。")
` `page.scroll.to_bottom()
` `continue # 跳過該貼文
` `# 如果找不到元素,就跳過這個貼文
` `common_class = 'x972fbf xcfux6l x1qhh985 xm0m39n x3nfvp2 x15zctf7 xln7xf2 xk390pu xdj266r x1mh8g0r x1j4z8aw x2pgyrj xl1lypt x5th0yj xexx8yu x4uap5 x18d9i69 xkhd6sd x11njtxf'
` `elements = post.eles(f'.{common_class}', timeout=2)
` `# 檢查按讚數是否存在
` `if len(elements) < 2:
` `print("按讚數或留言數被隱藏,跳過此貼文。")
` `consecutive_fail_count += 1 # 連續失敗次數加 1
` `total_fail_count += 1 # 累積失敗次數加 1
` `if consecutive_fail_count >= 10 or total_fail_count >= 40:
` `print(f"{account} 累積 {total_fail_count} 次或連續 {consecutive_fail_count} 次獲取失敗,跳過該 KOL。")
` `skip_kol.append(account)
` `delete_kol_data(connection, account) # 刪除 KOL 資料
` `return
` `continue
` `#如果大於等於 2
` `elif len(elements) == 2 or len(elements) > 2:
` `# 如果成功獲取數據,重置連續失敗次數
` `consecutive_fail_count = 0
` `full_link = link # 加上完整網址
` `post_key = f"{account}\_{post_number:03d}" # 編號鍵值
` `post_dict[post\_key] = full_link # 加入字典
` `post_number += 1 # 編號遞增
` `added_new_post = True # 新增貼文
` `post_set.add(link)
` `unique_posts.append(full_link)
` `likes_count = elements[0].text
` `if likes_count.endswith('萬'):
` `likes_count = int(float(likes_count.strip('萬')) \* 10000)
` `else:
` `likes_count = int(likes_count)
` `comments_count = elements[1].text
` `if comments_count.endswith('萬'):
` `comments_count = int(float(comments_count.strip('萬')) \* 10000)
` `else:
` `comments_count = int(comments_count)
` `print(f"帳號: {account}, 編號: {post_key}, 按讚數: {likes_count}, 留言數: {comments_count}, 連結: {full_link}")
` `insert_post_data(connection, post_key, account, likes_count, comments_count, full_link)
` `# 當達到 target_post_num 時,結束爬取,換下一個 KOL
` `if post_number > target_post_num:
` `return
` `except IndexError:
` `print("發生 IndexError,跳過此貼文。")
` `continue # 當 `elements` 長度不足時跳過
` `else:
` `print("未找到 <a> 標籤")
` `# 檢查這次爬取是否有新增貼文
` `if not added_new_post:
` `no_new_post_count += 1 # 無新增貼文次數加 1
` `print(f"第 {i + 1} 次爬取無新增貼文,連續無新貼文次數:{no_new_post_count}")
` `if no_new_post_count >= 3: # 若連續 3 次無新貼文,結束爬取
` `print(f"{account} 貼文數量不足,換下一個 KOL")
` `break
` `else:
` `no_new_post_count = 0 # 如果有新增貼文,重置計數
` `# page.wait(2)
` `print(f"不重複的貼文數量:{len(unique_posts)}")
` `# 顯示有哪些 KOL 被跳過
` `print("跳過的 KOL:", skip_kol)
四、打好基礎功 — 10 分鐘快速了解爬蟲用 HTML
| HTML 是什麼?簡單拆解基本結構
HTML 是一種標記語言,也是所有網頁背後的構成基礎,學習爬蟲的第一步便是學會解析 HTML,從中找出有用的資訊。
HTML 的整體架構就好像一個漢堡包,最上面會需要有麵包(head),把中間的起司、番茄跟肉(body — 主要內容)夾住。以下是一個簡單的 HTML 文件釋例:
<!DOCTYPE html>
<html>
<head>
` `<title>我的第一個網頁</title>
</head>
<body>
` `<h1>歡迎來到我的網站</h1>
` `<p class="content">這是一段段落文字。</p>
` `<a href="https://example.com">這是一個超連結</a>
</body>
</html>
| 那些你爬得到的標籤們:常見 HTML 元素速查
<html>:整個 HTML 文件的開始與結束。<head>:網頁的標頭部分,包含網頁標題、描述、CSS 樣式表等資訊。<title>:瀏覽器標籤上的網頁名稱。<body>:網頁的主要內容,包括文字、圖片、連結等。<h1>、<h2>、<h3>:標題文字,h1 為最大標題。<p>:段落文字。<a>:超連結,href 指定連結的網址。<img>:圖片,src 指定圖片路徑,alt 為圖片替代文字。<div>:區塊容器(可以塞東西),通常用於組織網頁結構。<span>:行內元素(更小的容器),通常用來標記小範圍的內容。
| 抓對目標最重要!快速定位你要的資料
在爬蟲時,我們需要找出網頁中我們感興趣的部分。如同上文所述,若我們想爬取 Instagram 貼文的內容,可以使用**滑鼠右鍵的「檢查」或是瀏覽器開發者工具(F12)**來檢視 HTML,找到貼文的標籤位置。
例如,Instagram 的貼文可能包含以下 HTML 結構:
<div class="C4VMK">
` `<span>這是一則 Instagram 貼文的內容。</span>
</div>
在爬蟲程式中,我們就可以使用 div.C4VMK span 來抓取這段內容。
| 四種資料擷取方式一次整理:Python、element、XPath、CSS 選擇器
1. 使用 Python 擷取並解析 HTML(以 DrissionPage 為例):
from DrissionPage import WebPage
# 建立網頁物件
page = WebPage()
# 請求 Instagram 貼文頁面
page.get('https://www.instagram.com/p/example/')
# 擷取貼文內容
txt = page.ele('.C4VMK span').text
print(f'貼文內容: {txt}')
這樣就能成功擷取 Instagram 貼文的內容了!
2. 使用 element 抓取資料:
有時,我們不僅想獲取單個元素的內容,還可能想獲取整個 HTML 元素 以進一步處理。這時候可以使用 element 來獲取目標元素,並對其進行進一步分析。
from DrissionPage import WebPage
# 初始化 DrissionPage
page = WebPage()
# 取得貼文的整個 div 元素
post_element = page.eles('.C4VMK')
# 從該元素中提取作者、日期、內容
author = post_ele('.author').text
date = post_ele('.date').text
post_content = post_ele.e('.post-content').text
# 輸出結果
print(f'發文者: {author}')
print(f'發文時間: {date}')
print(f'貼文內容: {post_content}')
3. 使用 XPath 抓取特定的 HTML 元素:
# 使用 XPath 抓取 Instagram 貼文內容
author = page.e('//div[@class="C4VMK"]/span[@class="author"]').text
date = page.e('//div[@class="C4VMK"]/span[@class="date"]').text
post_content = page.e('//div[@class="C4VMK"]/span[@class="post-content"]').text
print(f'發文者: {author}')
print(f'發文時間: {date}')
print(f'貼文內容: {post_content}')
4. 使用 CSS 選擇器,更靈活地抓取資料:
from DrissionPage import WebPage
# 模擬載入 HTML(在實際爬蟲時應該從網頁獲取)
html = """<div class='C4VMK'>
` `<span class='author'>用戶名稱</span>
` `<span class='date'>2024-03-01</span>
` `<span class='post-content'>這是一則 Instagram 貼文的內容。</span>
</div>"""
# 初始化 DrissionPage(使用本地 HTML)
page = WebPage()
page.load(html) # 直接載入 HTML 字串
# 選取貼文的 div 元素
post_element = page.e('css:.div.C4VMK')
# 提取作者、日期、內容
author = post_element.e('css:.span.author').text
date = post_element.e('css:.span.date').text
post_content = post_element.e('css:.span.post-content').text
# 輸出結果
print(f'發文者: {author}')
print(f'發文時間: {date}')
print(f'貼文內容: {post_content}')
*select_one 方法可以讓我們使用 CSS 選擇器來抓取單個元素,而 select 則可以抓取多個元素。
五、工具才是生產力 — 三大爬蟲套件推薦與比較
| BeautifulSoup:簡單好上手的新手首選
1. 特點
- 快速高效,適用於靜態網頁(無 JavaScript 動態渲染的網站)。
- 與 requests 搭配使用,獲取 HTML 內容後快速解析。
- 資源占用極低,比 Selenium 和 DrissionPage 更輕量級。
2. 適用場景
- 靜態網頁爬取,如新聞、論壇、簡單的 API。
- 解析已獲取的 HTML,如從 Selenium 或 Requests 獲取並解析 HTML。
- 純資料提取,無需與網站進行互動,如點擊按鈕、登入...等。
3. 缺點
- 無法處理 JavaScript,如果網站依賴 JavaScript 渲染內容,則無法獲取完整數據。
- 需要與 requests 或 urllib 搭配使用,無法單獨完成動態操作。
4. 範例代碼
import requests
from bs4 import BeautifulSoup
url = "https://example.com"
response = requests.get(url) # 獲取網頁 HTML
soup = BeautifulSoup(response.text, "html.parser") # 解析 HTML
print(soup.title.text) # 獲取網頁標題
| Selenium:動態網站的最佳幫手
1. 特點
- 適用於 JavaScript 渲染的網站,可模擬用戶的點擊、輸入、滾動等操作。
- 支援多種瀏覽器(Chrome、Firefox、Edge)。
- 適合測試自動化,如表單填寫、UI 測試、登入驗證。
2. 適用場景
- 需要與網站交互(點擊按鈕、登入、滾動加載)。
- 需要模擬真實用戶行為(避免被反爬機制攔截)。
- 需要處理 JavaScript 加載的動態內容。
3. 缺點
- 速度慢,資源占用高(啟動瀏覽器比 requests 或 DrissionPage 慢很多)。
- 易被網站偵測(許多反爬蟲機制可檢測 Selenium 瀏覽器)。
- 需要手動管理 WebDriver(如 chromedriver.exe 版本更新問題)。
4. 範例代碼
from selenium import webdriver
driver = webdriver.Chrome() # 啟動瀏覽器
driver.get("https://example.com") # 打開網頁
print(driver.title) # 獲取網頁標題
driver.quit() # 關閉瀏覽器
| DrissionPage® — 講者激推!瀏覽器 & 請求工具全能型選手
1. 特點
- 同時支援 瀏覽器(Selenium)和請求(Requests)兩種模式,能夠在效率與靈活性之間切換。
- 適合需要登入的網站,能夠用瀏覽器獲取 cookies 並轉換到 requests 模式,提高爬取效率。
- 支援無頭模式(Headless),節省資源。
2. 適用場景
- 需要 動態內容(JS 渲染的頁面),但不想用純 Selenium。
- 需要 自動切換 瀏覽器與請求模式,提高爬取效率(如登入後的請求)。
- 需要 低調爬取,降低網站風險(因為比 Selenium 更接近 requests)。
3. 缺點
- 使用門檻稍高,需要熟悉 瀏覽器模式(Browser Mode) 與 請求模式(Request Mode) 的轉換
- 相對於 requests + BeautifulSoup,依然會有瀏覽器的開銷。
4. 範例代碼
from DrissionPage import WebPage
page = WebPage() # 啟動瀏覽器
page.get("https://example.com") # 打開網站
print(page.soup.title.text) # 獲取網頁標題
| 套件比較總整理:選擇最適合你的那一個
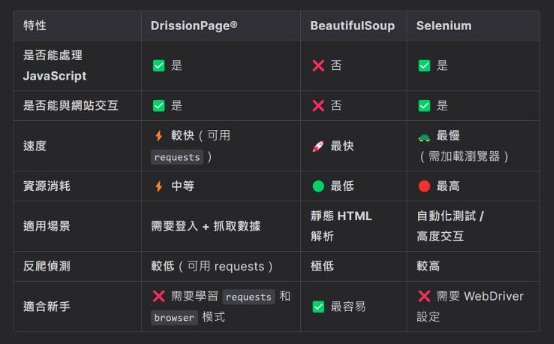 DrissionPage vs. BeautifulSoup vs. Selenium 多層面比較
DrissionPage vs. BeautifulSoup vs. Selenium 多層面比較
由此可知,我們可以這樣選擇合適的工具:
1. 如果是靜態網頁(無 JavaScript)→ BeautifulSoup + Requests
- 快速、簡單、資源佔用少。
- 適合新聞、簡單 API、論壇等靜態內容。
2️. 如果需要瀏覽器控制,但想提高效率 → DrissionPage
- 適合需要登入(Cookies 共享)、部分 JavaScript 內容,但不希望完全依賴 Selenium。
- 能自動在 requests 和 browser 之間切換,比 Selenium 高效。
3️. 如果需要完整模擬用戶行為(點擊、滾動、輸入)→ Selenium
- 適用於 動態網站(如無限滾動、Ajax 請求)。
- 需要處理 登入、點擊按鈕、填寫表單 等操作。
本次社課透過深入淺出的介紹,帶大家了解資料的種類、網站渲染原理、常見的數據來源與爬蟲的基本運作邏輯,為後續的實作打下堅實的基礎。
從今天起,資料不再遙不可及,只要掌握正確方法,我們也能透過程式從浩瀚的網路中挖掘出屬於自己的資訊寶藏!